Data Engineering - DataFrame(pandas) 6-2
Pandas
데이터를 수집하고 정리하는데 최적화된 도구
- 오픈소스
판다스 자료구조 vs. 파이썬 기본 자료구조 list, dictionary
- 판다스는 시리즈(Series)와 데이터프레임(DataFrame)이라는 구조화된 데이터 형식을 제공
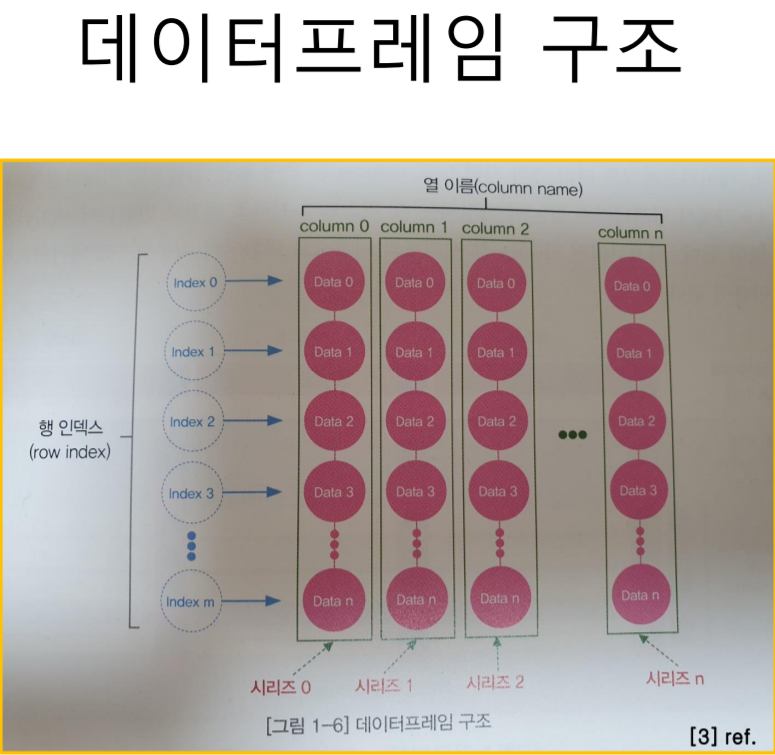
데이터 프레임이란?
- 2차원 배열 구조
- R 프로그램에서 유래
- 2차원은 열과 행으로 만들어지며, 각각의 열은 시리즈 객체
- 열과 행이 사용하는 주소는 각각 행 인덱스(row index)와 열 이름 (column name 또는 label)
- 열은 공통의 속성을 갖는 일련의 데이터
- 행은 개별 관측대상에 대한 다양한 속성 데이터들의 모음인 레코드 (record)
시리즈
- 시리즈는 데이터가 순차적으로 나열된 1차원 배열의 형태
- 인덱스Index와 데이터 값Value이 일대일 대응
- 키 Key와 값Value이 짝을 이루는 딕셔너리Dictionary와 비슷한 구조
시리즈 만들기
- 시리즈는 딕셔너리와 구조가 비슷하기 때문에
딕셔너리를 시리즈로 변 환하는 방법을 많이 사용
- 리스트를 시리즈로 변환하는 경우, 인덱스 구조를 이해하면 됨
1) 딕셔너리 -> 시리즈 변환
import pandas as pd
dict_data = {'a':1, 'b':2, 'c':3}
#dictionary -> series
sr = pd.Series(dict_data)2) 리스트 -> 시리즈 변환 : (default) 정수형 위치 인덱스
list_data =['2019-01-02', 3.14, 'ABC', 100, True]
#list -> series
sr = pd.Series(list_data)※ 인덱스 구조
두 종류의 인덱스 표현
1. 정수형 위치 인덱스
2. 인덱스 이름 또는 인덱스 라벨
원소 선택
- 원소의 위치를 나타내는 인덱스를 이용하여 시리즈의 원소를 선택 vs. 리스트 인덱싱
- 대괄호 [ ] 에 두 가지 인덱스 모두 사용 가능
import pandas as pd
dict_data = {'a':1, 'b':2, 'c':3}
sr = pd.Series(dict_data)
sr['b']
sr[1:2]
sr['b':'c']
데이터 프레임 만들기
1) Dictionary 자료구조를 DataFrame 으로 변환하여 생성
- 딕셔너리의 key는 DataFrame의 열이름으로
-딕셔너리의 list로 된 value는 DataFrame의 열로
import pandas as pd
#dictionary -> DataFrame
Dict_data = {'name' : ['Jerry', 'Riah', 'Paul'],
'algol' : ['A', 'A+', 'B'],
'basic' : ['C', 'B', 'B+'],
'c++' : ['B+', 'C', 'C+']
}
df = pd.DataFrame(dict_data)
2) 2차원 리스트 자료구조를 DataFrame 으로 변환하여 생성
- 생성자의 인자로 행 인덱스와 열 이름 설정 가능
index=[ ], columns=[ ]
import pandas as pd
#2차원 List -> DataFrame
list_data = [[15,'남','덕영중'],
[17, '여','수리중'],
[16, '여','연수중']
]
df = pd.DataFrame(list_data)
행/열 삭제
- df1 = df.drop( '예은‘ ) : df는 그대로, 삭제된 값 df1에 반환
- 인자1 : 행 인덱스, 열 이름 또는 리스트
- 인자2 : 행 선택 axis=0 (default) , 열 선택 axis=1
#list_data는 이전 예제 참조
df = pd.DataFrame(list_data, index=['준서', '예은', '길동'],
columns=['나이', '성별', '학교'])
#행 삭제
df1 = df.drop('예은')
df2 = df.drop(['준서','길동'])
#열 삭제
df5 = df.drop('성별', axis=1)
행 선택
loc 와 iloc 인덱서
- loc는 인덱스 명으로 선택
- iloc는 정수형 위치 인덱스로 선택

슬라이싱
Ex) iloc[3:7] : 정수형 위치 인덱서로, 3행부터 6행까지 선택 (7은 제외)
#df는 이전 예제 참조
#행선택
sr1 = df.loc['길동']
sr2 = df.iloc[0]
#l2개이상의 행 list형태로
df1 = df.loc[['준서','길동']]
df2 = df.iloc[[0,2]]
#범위 slicing
df3 = df.loc['예은':'길동']
df4 = df.iloc[0:2]
열 선택
- 데이터프레임의 열 데이터를 1개만 선택할 때는,
대괄호 [ ] 안에 열 이름 을 따옴표와 함께 입력
- 대괄호 안에 열 이름의 리스트를 입력하면
리스트의 원소인 열 모두 선 택하여 데이터프레임으로 반환
#df는 이전 예제 참조
#열선택
sr5 = df['나이']
#2개이상의 열 list형태로
df5 = df[['나이', '학교']]
원소 선택
- 데이터프레임의 행 인덱스와 열 이름을 [ 행 , 열 ] 형식의 2차원 좌표로 입력하여 원소 위치를 지정
- 원소 선택은 시리즈 및 데이터프레임 단위로 반환도 가능
#df는 이전 예제 참조
#원소선택
el1 = df.loc['예은','학교']
el2 = df.iloc[1, 2]
#2개이상의 열 iist형태로
sr1 = df.loc['준서', ['나이', '학교']]
#2개이상의 행,열 슬라이싱
df1 = df.loc['준서':'예은','나이':'학교']
행/열 추가
#df는 이전 예제 참조
df1 = df.copy()
#열추가
df1['수학'] = 80
df1['과학'] = [90, 80, 70]
#행추가
df1.loc['희수'] = [15, '남', '반포중', 100, 95]
#기존행 복사
df1.loc['수연'] = df1.loc['예은']
#원소값 변경
df1.loc['예은','수학']=75
df1.iloc[1,4]=75
df1.loc['예은',['수학','과학']]=85, 90
※ 이전 Pandas 사용 자료 읽기 리뷰
데이터 읽기
1. pandas.read_csv( )
import pandas as pd
df = pd.read_csv('data-text.csv', encoding='utf-8')
df2. pandas.read_json( )
import pandas as pd
df = pd.read_json('data-text.json') # encoding : default is ‘utf-8’
df
데이터 저장 방법
1. dataframe.to_csv( )
import pandas as pd
file_path = 'data-text.csv'
df = pd.read_csv(file_path, encoding='utf-8')
#iloc인덱서 & slicing
df100 = df.iloc[:100]
#csv write
df100.to_csv('data-text100.csv')2. dataframe.to_sql()
#1. DB 연결
con = sqlite3.connect("C:/Temp/sqlite3/test.db")
# DataFrame 생성 예
data = {'name' : ['Jerry', 'Riah', 'Paul'],
'algol' : ['A', 'A+', 'B'],
'basic' : ['C', 'B', 'B+'],
'c++' : ['B+', 'C', 'C+']
}
df = pd.DataFrame(data)
#2. DB 저장
df.to_sql('score',con, if_exists='append', index=False)
#3. DB 연결 종료
con.close()